
Del dato a la gota: uso de Inteligencia Artificial para la detección de
fugas de agua en Chihuahua
Dr. Aarón Heriberto Narváez Burciaga
Universidad Autónoma de Chihuahua
Dr. Jesús Roberto López Santillán
Universidad Autónoma de Chihuahua
Dr. Luis Carlos González Gurrola
Universidad Autónoma de Chihuahua
Resumen
La pérdida de agua por fugas en las redes de distribución representa uno de los mayores desafíos para el manejo sostenible de este recurso. En países en desarrollo, se estima que más del 40 % del agua enviada a la red se desperdicia, mientras que en algunas ciudades del estado de Chihuahua estas pérdidas superan el 50 %. Ante este panorama, la inteligencia artificial (IA), una tecnología capaz de identificar patrones y generar información útil a partir de grandes cantidades de datos, surge como una herramienta prometedora para mejorar la detección de fugas. Este artículo explora cómo la IA puede aprovechar la información recopilada por los sistemas de monitoreo de las redes hidráulicas para localizar fallas con mayor precisión, reducir el desperdicio de agua y optimizar la gestión de los recursos hídricos. Además, presenta ejemplos de estrategias innovadoras que combinan modelos digitales y aprendizaje automático para enfrentar este problema. Comprender estas tecnologías permite vislumbrar nuevas oportunidades para proteger un recurso esencial para la sociedad y avanzar hacia un uso más eficiente y sustentable del agua.
Introducción
"Gota a gota, el agua se agota", advertía una popular campaña publicitaria promovida por la Comisión
Nacional del Agua (CONAGUA) a finales de los años ochenta. Esa campaña buscaba concientizar a la
población sobre la importancia de cuidar hasta la más mínima gota de agua, anticipando una posible
escasez. Sin embargo, 40 años después de aquella campaña, México sigue enfrentando un serio problema
relacionado con sus recursos hídricos: de cada 10 litros de agua que se utilizan, 4 se desperdician
[1].
En 2006, el Banco Mundial (World Bank Group, WBG) [1] estimó que, a nivel global,
aproximadamente el
35 % del agua distribuida a través de las redes de distribución se perdía. Estas estimaciones se
realizaron considerando los países en desarrollo y se traducían en una pérdida de aproximadamente 45
millones de metros cúbicos (m³) diarios. Esa cantidad de agua llenaría más de 25 estadios Azteca.
Estimaciones más recientes, como las realizadas por Liemberger y Wyatt [2], son menos conservadoras
y calculan que las pérdidas diarias ascienden a 256 millones de m³ en los países en desarrollo (más
de 143 estadios Azteca) y a 69.1 millones de m³ en América Latina y el Caribe (más de 38 estadios
Azteca).
En México, las cifras estimadas son de aproximadamente 12.5 millones de m³ diarios (más de 7
estadios Azteca), lo que representa el 40 % del total de agua enviada a través de las redes de
distribución. Estas cifras contrastan con la realidad de los países desarrollados, donde la pérdida
es de aproximadamente el 20 %, con algunos casos, como Países Bajos y Dinamarca, donde no excede el
7 %. La Tabla 1 presenta un comparativo del desperdicio de agua por día para algunos países en
desarrollo (Brasil, Nigeria y México), así como para algunos países desarrollados (Alemania, China,
Dinamarca, Estados Unidos de América y Países Bajos).
Tabla 1. Cifras estimadas de agua desperdiciada para algunos países [2].
| País | Agua desperdiciada (m³/día) | Porcentaje de agua desperdiciada |
| Alemania | 2,030,621 | 15 % |
| Brasil | 18,872,182 | 39 % |
| China | 44,688,202 | 21 % |
| Dinamarca | 69,888 | 7 % |
| Estados Unidos de América | 39,068,076 | 20 % |
| Nigeria | 738,259 | 39 % |
| México | 12,425,811 | 40 % |
| Países Bajos | 146,196 | 5 % |
Por otra parte, en el estado de Chihuahua, las pérdidas de agua representan un desafío crítico para
la sostenibilidad hídrica. De acuerdo con la CONAGUA, el estado presenta una eficiencia física del
52 % [3, p. 66]. Esto implica que el 48 % del volumen total inyectado a la red de distribución no
llega a ser contabilizado, lo cual se atribuye, en parte, a fugas físicas en el sistema. Dado que la
mayor parte de la infraestructura se encuentra bajo tierra, es de esperarse que la localización de
fugas sea una tarea extenuante y costosa.
Los métodos convencionales combinan el monitoreo de la red con la inspección visual de las
tuberías.
Este enfoque suele ser lento y propenso a errores de interpretación. En este contexto, la
inteligencia artificial (IA), una tecnología capaz de identificar patrones y tomar decisiones a
partir de grandes cantidades de datos, emerge como una herramienta eficiente. Ha demostrado su
utilidad, por ejemplo, en la predicción de sequías mediante el análisis de imágenes satelitales.
Además, se utiliza para estimar la demanda hídrica, monitorear la calidad del agua y optimizar el
riego agrícola. Sin embargo, la efectividad de la IA depende de la información que recibe. Para
conocer los datos que pueden utilizarse en la detección de fugas, primero es necesario comprender,
de manera general, cómo funcionan los sistemas hidráulicos modernos.
Sistemas de distribución de agua
Los componentes principales de las redes de distribución de agua en zonas urbanas son el sistema de almacenamiento de agua tratada, las estaciones de bombeo y la red de tuberías para la distribución. En la Figura 1 se muestra una versión simplificada de un sistema moderno de distribución de agua que incluye elementos como pozos, bombas, unidades de monitoreo, sensores de presión, tanques de almacenamiento y medidores de consumo, diseñados para satisfacer las necesidades residenciales, agrícolas e industriales.
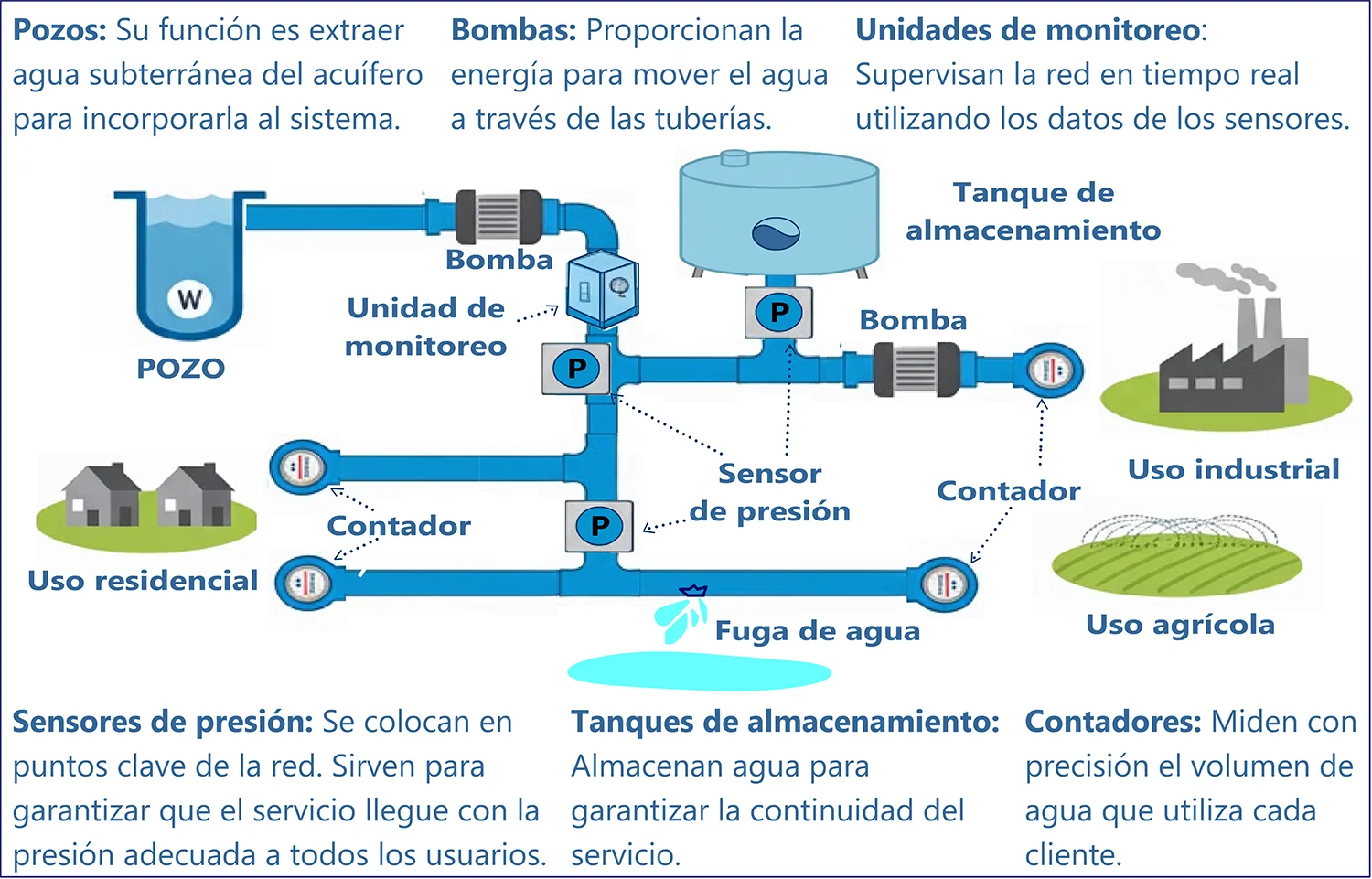
Figura 1: Representación simplificada de un sistema moderno de distribución de agua.
Para calcular la pérdida de agua se utiliza la métrica denominada "agua no contabilizada", que
corresponde a la diferencia entre el agua que se inyecta al sistema y la que finalmente registran
los medidores de los usuarios. Por ejemplo, si el sistema de distribución envía 1,000 litros a la
red y solo se contabilizan 600 en los medidores, se registra una pérdida de 400 litros; es decir, un
40 % del agua se pierde en el trayecto. No obstante, reducir esta cifra requiere pasar del simple
diagnóstico a la localización precisa, un reto que demanda, en primera instancia, modelar la red de
distribución para comprender su comportamiento hidráulico a partir de la topología de sus
componentes y de las leyes físicas que gobiernan el flujo.
Al ser la red de tuberías el elemento más abundante de un sistema de distribución, también
es el más
susceptible a fallos. Además, estas tuberías están expuestas a condiciones adversas derivadas del
entorno urbano. En Chihuahua, la mayoría de las tuberías se encuentran enterradas. Detectar fugas
mediante inspección visual resulta prácticamente imposible, salvo cuando la fuga es tan grande que
logra remover la tierra circundante. Para fines prácticos, la red puede simplificarse y
representarse como un grafo dirigido. Un grafo es una estructura matemática formada por nodos
(puntos) y aristas (conexiones) que permiten representar relaciones entre distintos elementos.
Esta representación permite simplificar la red y centrarse únicamente en:
- Nodos: puntos de unión, consumo, tanques, pozos, bombas, válvulas y otros elementos de la red.
- Aristas: tuberías que conectan los nodos.
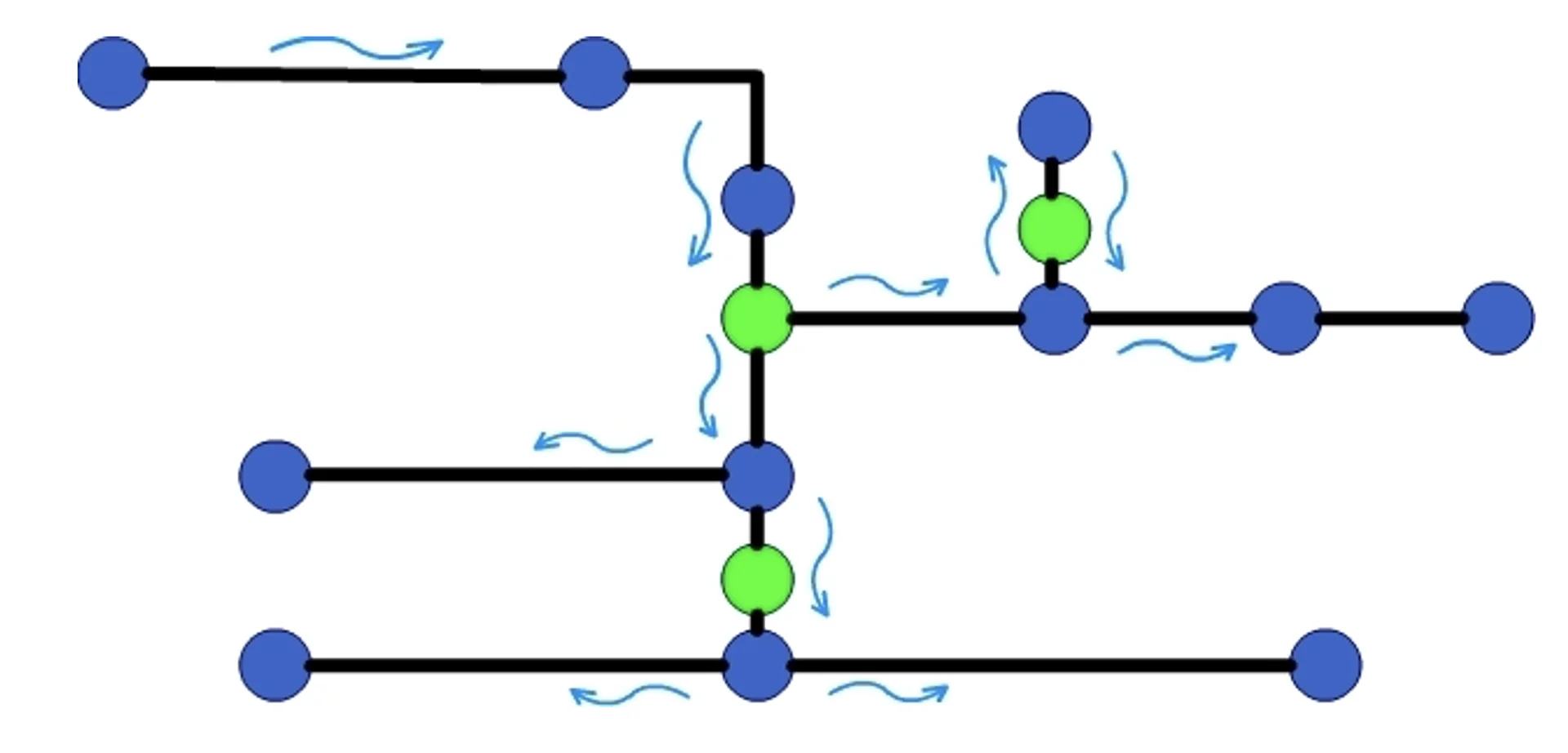
Figura 2: Grafo dirigido de un sistema moderno de distribución de agua basado en la red mostrada en la Figura 1.
En la práctica, las métricas más utilizadas en las redes de distribución de agua son el caudal
(cantidad de agua que circula por unidad de tiempo, generalmente expresada en litros por segundo) y
la presión (fuerza que ejerce el agua sobre las paredes de la tubería). Una presión demasiado baja
impide que el agua llegue adecuadamente a todos los usuarios, mientras que una presión excesiva
puede dañar las tuberías y otros componentes de la red.
Existe una relación directa entre la presión del agua y su caudal o flujo. En una tubería
cerrada y sin fugas, si ningún usuario consume agua, no existe flujo y la presión permanece estable.
Sin embargo, cuando se abre una llave o se produce una fuga, el agua comienza a desplazarse por la
tubería, lo que provoca una caída de presión. Entonces surge una pregunta fundamental: ¿cómo
determinar si esa caída de presión se debe a una fuga o simplemente al consumo normal de los
usuarios?
Una estrategia común consiste en asumir que, para un tramo de red con múltiples usuarios, la
caída de presión debe mantenerse dentro de un rango habitual. Por ello, suele analizarse el
comportamiento de la presión durante las horas de menor demanda, bajo la premisa de que las
variaciones observadas en esos periodos podrían atribuirse a fugas. Sin embargo, en condiciones
reales, la cantidad de sensores de presión suele ser mucho menor que la cantidad de nodos presentes
en la red, lo que dificulta considerablemente la localización precisa de las fugas.
Agregar más sensores a una red hidráulica extensa y compleja podría parecer una solución
evidente, pero no necesariamente es la más conveniente. La adquisición e instalación de sensores
requiere una inversión significativa y, además, incrementa los costos asociados al mantenimiento, la
operación y el monitoreo continuo. Por esta razón, el objetivo principal es aprovechar al máximo la
infraestructura ya existente.
En este contexto cobran importancia los sistemas de Control de Supervisión y Adquisición de
Datos (SCADA, por sus siglas en inglés de Supervisory Control and Data Acquisition). Los sistemas
SCADA permiten supervisar y controlar de manera remota distintos elementos de la red, como bombas y
válvulas, además de monitorear y almacenar variables históricas como la presión, el flujo y la
calidad del agua [4].
En una red hidráulica moderna pueden operar miles de sensores de manera simultánea. Cada uno
de ellos envía periódicamente sus lecturas a los sistemas SCADA, generando enormes volúmenes de
datos. Sin embargo, existe una diferencia fundamental entre datos e información. Los datos son
registros aislados, mientras que la información surge cuando esos datos adquieren contexto y
significado útiles para la toma de decisiones. Al proceso de extraer información valiosa a partir de
grandes conjuntos de datos se le conoce como minería de datos.
Es precisamente en esta transformación de datos en información donde la inteligencia
artificial ha adquirido una gran relevancia, convirtiéndose en una de las herramientas más poderosas
para la minería de datos. La IA permite automatizar la conversión de grandes volúmenes de datos en
información útil y accionable. En el caso particular de las redes hidráulicas, ha demostrado ser
capaz de reducir el área de búsqueda de fugas e incluso detectar anomalías en tiempo real.
De los datos a la información: cómo se utiliza la IA en la detección de fugas
Modelar con exactitud el comportamiento de una red hidráulica es una tarea extremadamente compleja.
Esto se debe a la variabilidad de sus condiciones de operación, al envejecimiento progresivo de la
infraestructura y a la existencia de numerosas variables desconocidas, como los consumos reales no
medidos y las fugas que pasan inadvertidas. Ante este escenario de incertidumbre, la IA busca
facilitar la comprensión del sistema mediante el aprendizaje a partir de su historial operativo.
La definición de inteligencia artificial es amplia e incluye todos aquellos algoritmos
diseñados para realizar tareas que normalmente requieren capacidades cognitivas humanas, como el
razonamiento, el aprendizaje, la memoria o la atención. Estas capacidades permiten resolver
problemas y tomar decisiones. Sin embargo, la IA no intenta reproducir completamente el
comportamiento humano, sino emular aquellas funciones específicas necesarias para resolver una tarea
o automatizar un proceso.
Como resultado, la IA puede dividirse en diversas subramas según el objetivo que persiguen.
Entre las más conocidas se encuentran la robótica, el procesamiento del lenguaje natural, la visión
artificial y el aprendizaje automático (Machine Learning, ML). El aprendizaje automático es una rama
de la IA que permite identificar patrones de forma automática a partir de datos históricos. Debido a
esta capacidad, es una de las herramientas más adecuadas para abordar el problema de la detección de
fugas en redes hidráulicas.
Aunque formalmente un algoritmo se define como una secuencia lógica de instrucciones que
transforma una entrada en una salida, en el aprendizaje automático su función principal es
identificar patrones y relaciones estadísticas dentro de los datos históricos. En este contexto,
resulta importante distinguir entre algoritmo y modelo. El algoritmo corresponde al procedimiento de
aprendizaje, mientras que el modelo es el resultado final de dicho proceso, es decir, una
representación matemática cuyos parámetros han sido ajustados para realizar una tarea específica. En
términos prácticos, los algoritmos de ML se utilizan para entrenar modelos capaces de transformar
datos en información útil para la toma de decisiones.
El aprendizaje de los modelos ocurre durante la etapa de entrenamiento, en la cual se
ajustan sus parámetros internos. Este proceso puede compararse con la mezcla de colores: el
algoritmo combina y modifica gradualmente colores básicos —equivalentes a sus parámetros— hasta que
la mezcla obtenida se aproxima lo más posible al color deseado, que representa la salida esperada.
Este procedimiento se repite numerosas veces y sobre grandes cantidades de datos, permitiendo que el
algoritmo identifique los patrones más relevantes.
En la Figura 3 se muestra el proceso general de entrenamiento de un modelo de aprendizaje
automático. Las entradas representan ejemplos conocidos, mientras que las salidas esperadas se
comparan con las predicciones generadas por el modelo para calcular un error. Posteriormente, ese
error se utiliza para ajustar los parámetros internos del modelo y mejorar su desempeño.
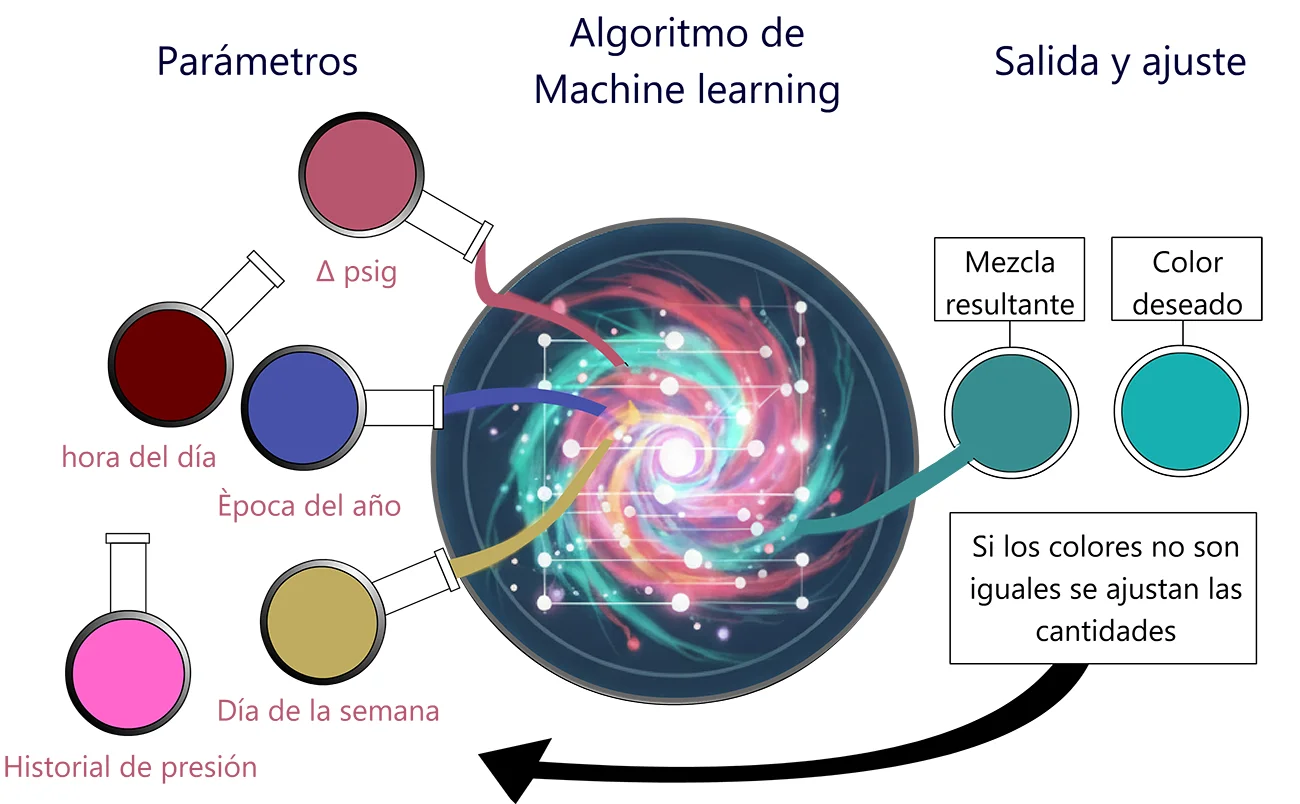
Figura 3: Proceso de entrenamiento de un modelo de aprendizaje automático. Creada mediante el rediseño manual de elementos generados por IA (Gemini de Google, 2026).
Es importante señalar que los algoritmos de aprendizaje automático se dividen generalmente en
supervisados y no supervisados. Los algoritmos supervisados, como el representado en la Figura 3,
utilizan etiquetas que relacionan los datos de entrada con una respuesta o evento específico; es
decir, trabajan con pares de dato-respuesta. Por su parte, los algoritmos no supervisados carecen de
estas etiquetas y se enfocan en identificar similitudes entre los datos para formar grupos, detectar
anomalías o generar representaciones más compactas de la información. A pesar de estas diferencias,
ambos enfoques comparten un principio fundamental: aprender patrones a partir de los datos. Por
ello, la calidad de los datos y la forma en que se representan son elementos clave para desarrollar
estrategias efectivas de detección de fugas mediante aprendizaje automático.
La importancia de las representaciones puede observarse en investigaciones como la realizada
por
Irofti y colaboradores [5]. En su estudio, los autores utilizaron una representación de la red
hidráulica en forma de grafo para simular distintos escenarios de fuga. A partir de estas
simulaciones identificaron patrones característicos asociados a diferentes ubicaciones de fuga. Su
metodología está diseñada para redes con una cantidad limitada de sensores y considera los consumos
esperados de los usuarios. Como consecuencia, una parte importante del procedimiento consiste en
estimar las presiones en los nodos que no cuentan con sensores a partir de la información disponible
en los nodos instrumentados. A pesar de esta limitación, el método logra localizar fugas dentro de
un área máxima de dos nodos de distancia con una precisión cercana al 98 %.
Otros enfoques emplean el concepto de gemelos digitales para la gestión de redes hidráulicas
[6],
[7]. Un gemelo digital es una representación virtual de una infraestructura real que integra
información sobre su estructura, sus componentes y su comportamiento operativo. En el caso de las
redes hidráulicas, estos modelos virtuales se complementan con herramientas de IA capaces de
predecir estados futuros de la red a partir de los datos históricos y de los patrones aprendidos
durante el entrenamiento.
Si el comportamiento observado en la red real difiere significativamente del comportamiento
predicho
por el gemelo digital, puede inferirse la presencia de una fuga o de alguna otra anomalía operativa.
De esta manera, el sistema no solo permite monitorear el estado actual de la infraestructura, sino
también anticipar posibles problemas antes de que se conviertan en fallas mayores.
La principal ventaja de la IA radica en su capacidad para aprender directamente de los datos
históricos de operación. Esto permite mejorar la detección y el diagnóstico de fugas, además de
favorecer la identificación temprana de zonas vulnerables dentro de la red. En consecuencia, la IA
debe entenderse como una herramienta complementaria que aprovecha la información recopilada por los
sistemas SCADA y se integra con los modelos hidráulicos convencionales para fortalecer la gestión de
los recursos hídricos.
Conclusiones y futuro del monitoreo inteligente
Las redes hidráulicas modernas operan bajo condiciones cambiantes y están sujetas a un desgaste
continuo provocado por el uso, el envejecimiento de los materiales y el crecimiento urbano. Debido a
que gran parte de esta infraestructura se encuentra enterrada, la detección de fugas mediante
inspección visual resulta poco práctica y, en muchos casos, imposible. Por ello, reducir el
desperdicio de agua requiere la implementación de tecnologías que permitan detectar fallas con mayor
rapidez y localizar con precisión las zonas afectadas.
La disponibilidad de grandes cantidades de datos históricos y operativos, proporcionados por
los
sistemas SCADA, convierte a la inteligencia artificial en una herramienta especialmente adecuada
para la detección de fugas en redes hidráulicas. Esta tendencia representa una evolución natural de
los sistemas actuales, al combinar el carácter reactivo de los métodos tradicionales con las
capacidades predictivas de la IA. Como resultado, es posible avanzar más allá de la simple detección
de fallas y acercarse al diagnóstico automático, la localización precisa de anomalías y la
identificación proactiva de áreas vulnerables dentro de la red.
Sin embargo, la eficacia de estas tecnologías depende directamente de la calidad, cantidad
y
disponibilidad de los datos. Aunque existen numerosos estudios que demuestran el potencial de la IA
para mejorar la gestión de las redes hidráulicas, son relativamente pocos los que documentan
implementaciones reales a gran escala. Además, cada sistema de distribución presenta características
particulares relacionadas con su infraestructura, patrones de consumo y condiciones de operación,
por lo que resulta necesario realizar análisis específicos para determinar cuáles tecnologías son
las más adecuadas en cada caso.
En el estado de Chihuahua, la implementación de metodologías que permitan optimizar el uso
del agua
constituye un elemento central de los planes hídricos de mediano y largo plazo. En este contexto,
desarrollar mecanismos eficientes para la detección de fallas en la red hidráulica es una necesidad
ineludible. Reducir el desperdicio de agua es fundamental para garantizar una gestión sustentable de
este recurso estratégico. Se trata de un desafío que debe asumirse de manera colectiva, combinando
innovación tecnológica, planeación y participación social para conservar el agua, gota a gota
Referencias
[2] R. Liemberger y A. Wyatt, “Quantifying the global non-revenue water problem,” Water Science and Technology: Water Supply, vol. 19, no. 3, pp. 831–837, abr. 2019. doi: https://doi.org/10.2166/ws.2018.129
[3] Comisión Nacional del Agua (CONAGUA), Situación del subsector agua potable, alcantarillado y saneamiento, edición 2025, Secretaría de Medio Ambiente y Recursos Naturales, Ciudad de México, México, 2025. [En línea]. Disponible en: https://www.gob.mx/conagua/documentos/situacion-del-subsector-agua-potable-drenaje-y-saneamiento
[4] S. A. Boyer, SCADA: Supervisory Control and Data Acquisition, 3.ª ed. Research Triangle Park, NC, Estados Unidos: International Society of Automation, 2009. [En línea]. Disponible en: https://www.isa.org/products/scada-supervisory-control-and-data-acquisition
[5] P. Irofti, L. Romero-Ben, F. Stoican y V. Puig, “Learning dictionaries from physical-based interpolation for water network leak localization,” IEEE Transactions on Control Systems Technology, vol. 32, no. 3, pp. 755–766, may. 2024. doi: https://doi.org/10.1109/TCST.2023.3329696
[6] S. Jun y D. Jung, “Exploration of deep learning leak detection model across multiple smart water distribution systems: Detectable leak sizes with AMI meters,” Water Research X, vol. 29, p. 100332, abr. 2025. doi: https://doi.org/10.1016/j.wroa.2025.100332
[7] T. A. Syed, M. A. Muhammad, A. A. AlShahrani, M. Hammad y M. T. Naqash, “Smart water management with digital twins and multimodal transformers: A predictive approach to usage and leakage detection,” Water, vol. 16, no. 23, p. 3410, nov. 2024. doi: https://doi.org/10.3390/w16233410